
Modern IoT sensor networks generate vast amounts of data that require robust cloud infrastructure for storage, processing, and analysis. This article explores effective strategies for integrating IoT systems with cloud platforms to extract meaningful insights from sensor data.
Cloud Platform Selection
When selecting a cloud platform for IoT deployments, organizations should consider their existing technology ecosystem and specific requirements. Major cloud providers offer specialized IoT services with distinct advantages:
Amazon AWS IoT Core provides direct MQTT integration and seamless connection with services like DynamoDB and Kinesis for real-time data processing. Google Cloud IoT Core excels at machine learning integration through services like TensorFlow and AutoML.
Microsoft Azure IoT Hub offers robust device management and strong integration with industrial protocols like OPC-UA.
Database Architecture for IoT Systems
A well-designed database architecture is crucial for handling the complex nature of IoT data. A recommended approach is implementing a two-tier database strategy that separates raw data ingestion from analytical processing.
Raw Data
NoSQL databases excel at handling raw IoT data due to their flexible schema design and high-throughput capabilities. Document databases are particularly well-suited for IoT data, as they can store complex nested structures that represent sensor readings along with associated metadata.
This includes device information, timestamps, location data, and various environmental readings. The schema-less nature of these databases allows for easy adaptation as sensor capabilities evolve or new types of measurements are added to the network.
Processed Data
A relational database should be carefully designed to support efficient querying and analysis of processed data. A typical schema might include tables for devices, readings, and maintenance logs, with appropriate relationships between them.
Time-series partitioning strategies can significantly improve query performance for large datasets. The analytics layer should also support aggregation and statistical analysis, enabling users to identify trends and patterns across different time scales and device groups.
Data Flow Architecture
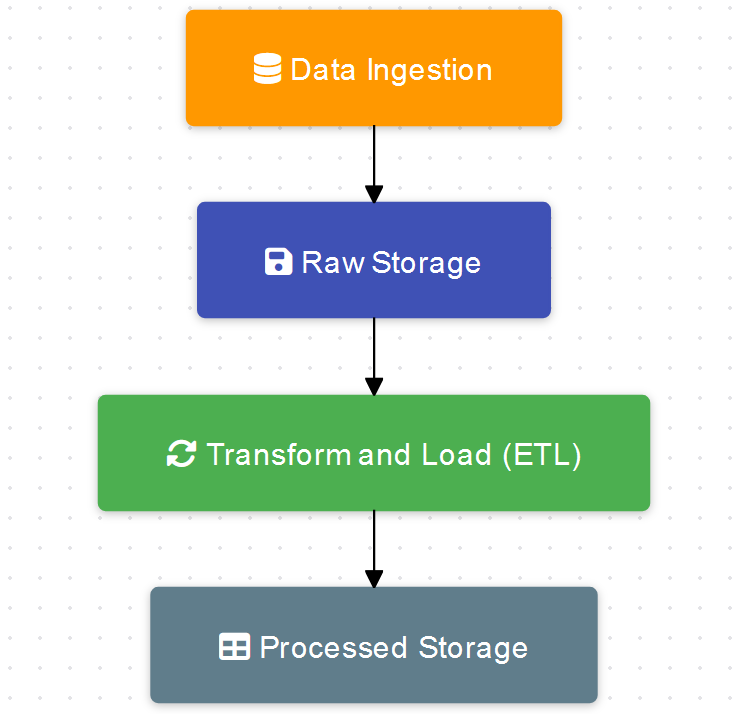
A robust IoT data pipeline typically consists of several key stages:
Data Ingestion
The initial stage involves collecting data from sensor nodes through a gateway system. This gateway should validate incoming data, add necessary metadata, and ensure reliable transmission to cloud storage. The gateway might also perform initial data formatting and basic error checking.
Raw Storage
Once data reaches the cloud, it’s stored in its original form in the NoSQL database. This preserves the complete historical record and allows for reprocessing if needed. The storage system should be designed to handle high-throughput writes while maintaining quick read access for recent data.
Transform and Load
ETL processes run continuously to prepare data for analysis. These processes clean the data, convert units if necessary, check for anomalies, and transform the data into a format optimized for analytical queries. This stage might also include data enrichment, such as adding weather data or other relevant external information.
Processed Storage
The processed data is stored in a structured database with a well-defined schema. This layer should support efficient querying and provide a stable interface for downstream analytics processes. The schema should accommodate both time-series data and related metadata, with appropriate indexing strategies for common query patterns.The processed data layer serves as a foundation for various analytical workflows
Example Pattern
Here’s an example architecture that implements these practices.
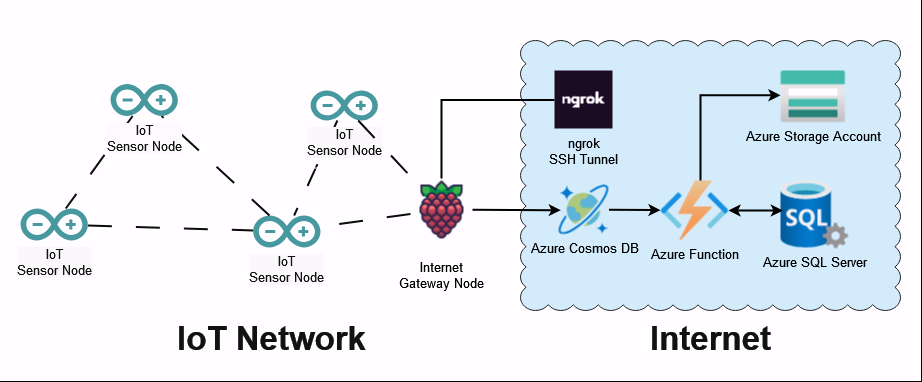
This cloud-based data processing system leverages Azure Cosmos DB for flexible raw data storage and Azure SQL Database for structured analysis, with data flowing from sensor nodes through an internet gateway and processed via Azure serverless functions. This architecture ensures scalability, efficient ETL workflows, and seamless access for environmental engineers to analyze the data from the IoT sensors.
Best Practices for Implementation
Design processing workflows to be idempotent and fault-tolerant, with comprehensive error handling. Implement monitoring for pipeline performance, tracking metrics like ingestion rates, latency, and error rates. Maintain appropriate partitioning strategies for time-series data to ensure sustained performance as datasets grow.
Future Considerations and Conclusion
As IoT deployments evolve, organizations must balance data lifecycle management, analytics integration, and security requirements. A well-designed data processing pipeline, separating raw and processed data, enables organizations to adapt to emerging technologies while maintaining data quality and analytical capabilities.