
Technical SEO refers to the process of optimizing the infrastructure of a website to help search engines crawl, index, and understand it more effectively. This involves a range of activities focused on improving the technical foundation of a site, including optimizing site speed, ensuring mobile friendliness, creating a clear site structure, using a well-organized robots.txt file, implementing structured data, and managing secure connections with HTTPS.
1. Optimize Page Speed
- Impact on SEO: Page speed is a critical SEO factor as it affects both user experience and Google’s ranking algorithms. A slow-loading page increases bounce rates, where users leave before interacting, which can signal to search engines that the page offers a poor experience. In response, Google might rank it lower, reducing organic visibility.
- How to Optimize: Use tools like Google PageSpeed Insights or GTmetrix to identify areas for improvement. Common tactics include:
- Compressing images
- Minimizing JavaScript and CSS files
- Enabling browser caching and content delivery networks (CDNs)
- Reducing server response times

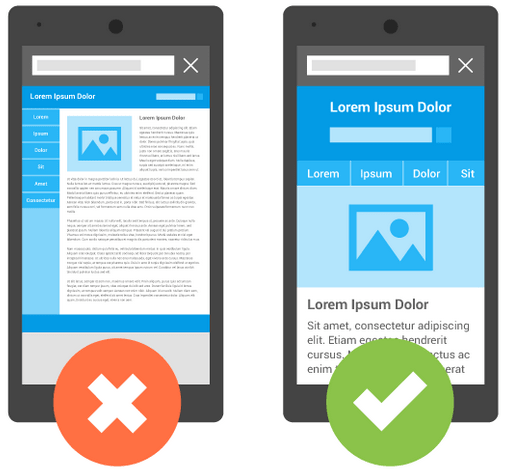
2. Optimize for Mobile
- Impact on SEO: With the rise of mobile browsing, Google moved to a mobile-first indexing approach. This means Google primarily uses the mobile version of a website for indexing and ranking. If a site isn’t mobile-friendly, it could result in lower rankings on both mobile and desktop search results.
- How to Optimize: Use responsive design, which adapts the layout to various screen sizes. Ensure fonts are readable on smaller screens, clickable elements are easy to interact with, and page load times are optimized for mobile devices.
3. Fix Crawling Errors
- Impact on SEO: Crawling errors occur when search engines can’t access certain pages on a site, which prevents them from indexing these pages. If valuable pages aren’t indexed, they won’t appear in search results, impacting organic reach.
- How to Fix: Regularly check Google Search Console for crawl error reports. Address issues like:
- Broken links (404 errors)
- Server errors (500-level errors)
- Redirect chains
- Disallowed pages in robots.txt

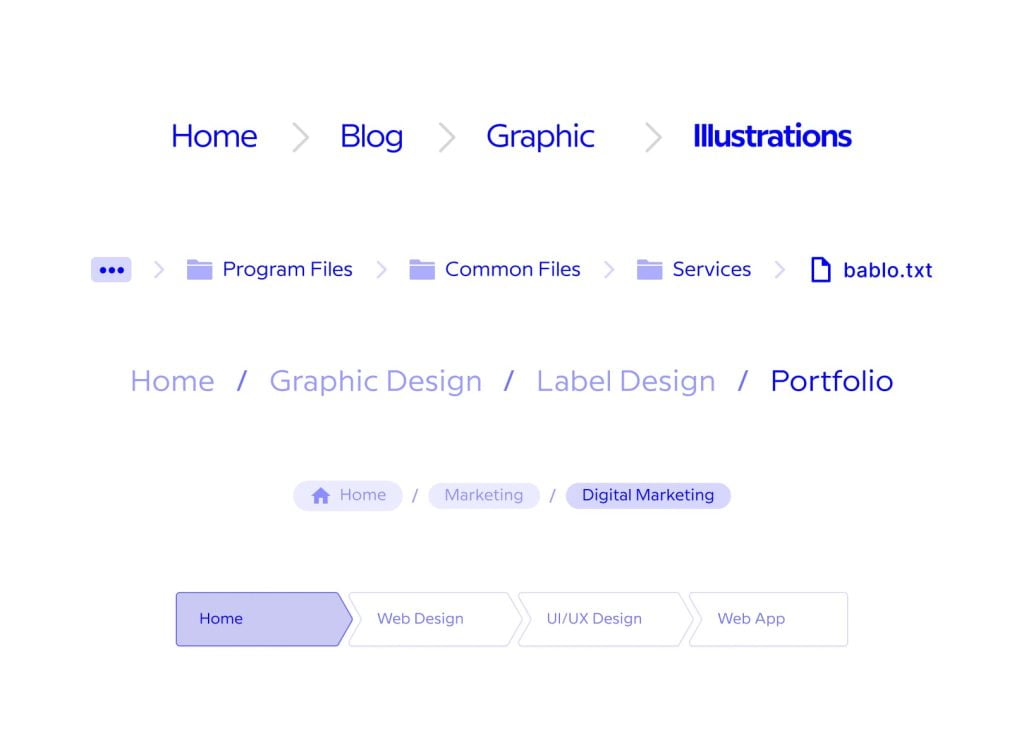
4. Implement Breadcrumbs
- Purpose: Breadcrumbs display the hierarchical path from the homepage to the current page. For example, a breadcrumb might show: Home > Category > Subcategory > Product.
- User Experience: They improve user navigation by helping visitors understand their location on the site and making it easy to go back to previous sections.
- SEO Benefits: Breadcrumbs improve internal linking and provide contextual cues to search engines, reinforcing the site’s structure. They often appear in Google search results, enhancing click-through rates.
5. Create XML Sitemaps
- Impact on SEO: XML sitemaps provide a roadmap for search engines to find and index a site’s content efficiently. While a sitemap doesn’t guarantee indexing, it helps guide search engine bots to important pages, especially on large or complex sites.
- How to Implement: Most CMS platforms have plugins or built-in tools to generate XML sitemaps. Regularly update the sitemap to reflect new or removed pages and submit it to Google Search Console for faster discovery and indexing.
- Include a link to your XML sitemap in the robots.txt file to help search engines find all the important pages.

6. Add Schema Markup
- Impact on SEO: Schema markup, also known as structured data, provides search engines with additional context about the page’s content. This can improve SERP visibility by enabling rich snippets, like star ratings, event details, product information, or recipe highlights, which can increase click-through rates (CTR).
- How to Implement: Use schema.org to define structured data for the most relevant information on each page. This can be added through HTML, JSON-LD, or microdata formats, with JSON-LD being Google’s preferred format. Testing through Google’s Rich Results Test ensures accurate implementation.

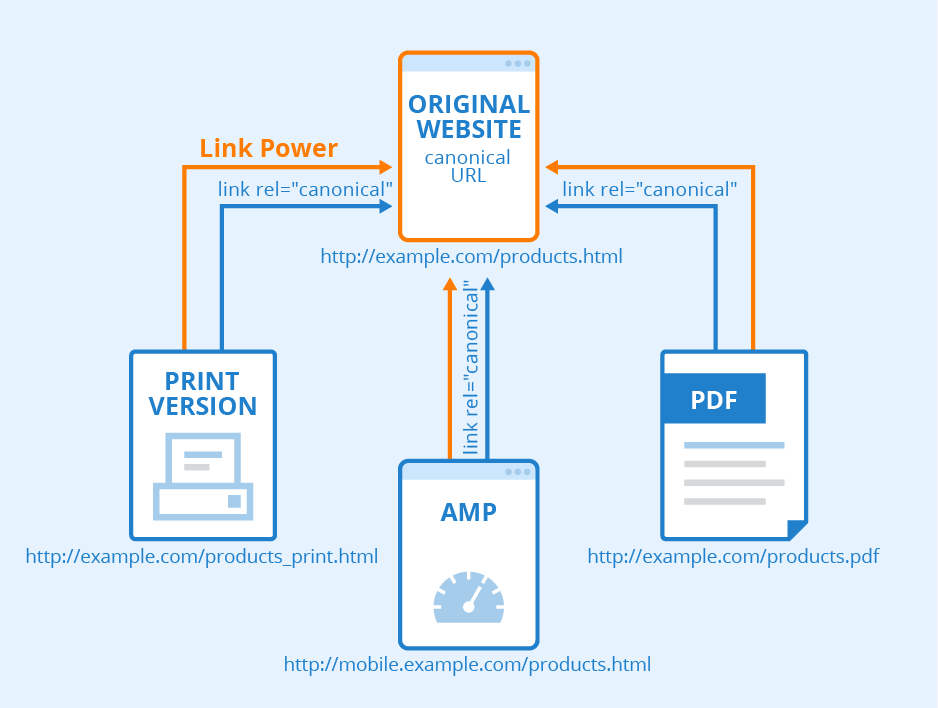
7. Use Canonical Tags
- Impact on SEO: Canonical tags help prevent duplicate content issues by indicating the “preferred” or “canonical” version of a page when there are duplicates. Without them, search engines might struggle to determine which version to rank, possibly diluting link equity and hurting SEO.
- How to Implement: For pages with similar content, use the canonical tag to point to the main version (e.g., <link rel=”canonical” href=”https://www.example.com/main-page” />). This can be particularly useful for e-commerce sites with similar products or blog sites with pagination.
8. Set Up SSL Certification
- Impact on SEO: An SSL certificate, signified by HTTPS in the URL, encrypts data transferred between the user’s browser and the server. Since 2014, Google has considered HTTPS a ranking factor as it provides a more secure browsing experience.
- How to Implement: Purchase an SSL certificate from a trusted Certificate Authority (CA) or use free services like Let’s Encrypt. After implementation, update internal links and use 301 redirects for HTTP to HTTPS migration. Ensuring all elements on the page load via HTTPS prevents “mixed content” errors that can disrupt the secure connection.

9. Identify Duplicate Content
First, use tools like Google Search Console, Screaming Frog, or third-party SEO tools like Ahrefs or SEMrush to scan your site. Look for identical or very similar content across pages, including:
- Use 301 Redirects: For pages that don’t need to exist as duplicates (e.g., outdated versions of a page), set up a 301 redirect to guide users and search engines to the correct page. This not only consolidates ranking signals but also improves user experience by funneling them to the right content.
- Consolidate Similar Content: If you have multiple pages targeting nearly identical keywords or themes, consider combining them into a single, comprehensive page. Not only does this reduce duplicate content, but it also strengthens that page’s authority.
- Avoid Duplicate Meta Tags: Duplicate meta titles and descriptions can also confuse search engines. Make sure each page has a unique title and description to help with ranking and click-through rates.
- Fix Duplicate Internal Links: If you have multiple internal links pointing to the same page with different URLs, update them to consistently use the preferred URL. This applies to links in menus, footers, and content links.
- Use Hreflang Tags for Multilingual Pages: If your site has different versions for various languages or regions, use the hreflang attribute to tell search engines which version to show to users based on their language or location. This prevents duplicate content issues across multilingual or regional pages.
- Set URL Parameters in Google Search Console: If duplicate content is caused by URL parameters (e.g., ?sort=price or ?ref=affiliate), configure these in Google Search Console. This way, Google knows how to handle different URL variations without treating them as unique pages.
- Noindex Unimportant Pages: For pages that aren’t meant to rank (e.g., login pages, duplicate archive pages), add a noindex meta tag. This tells search engines not to index those pages, which reduces the likelihood of duplicate content penalties.

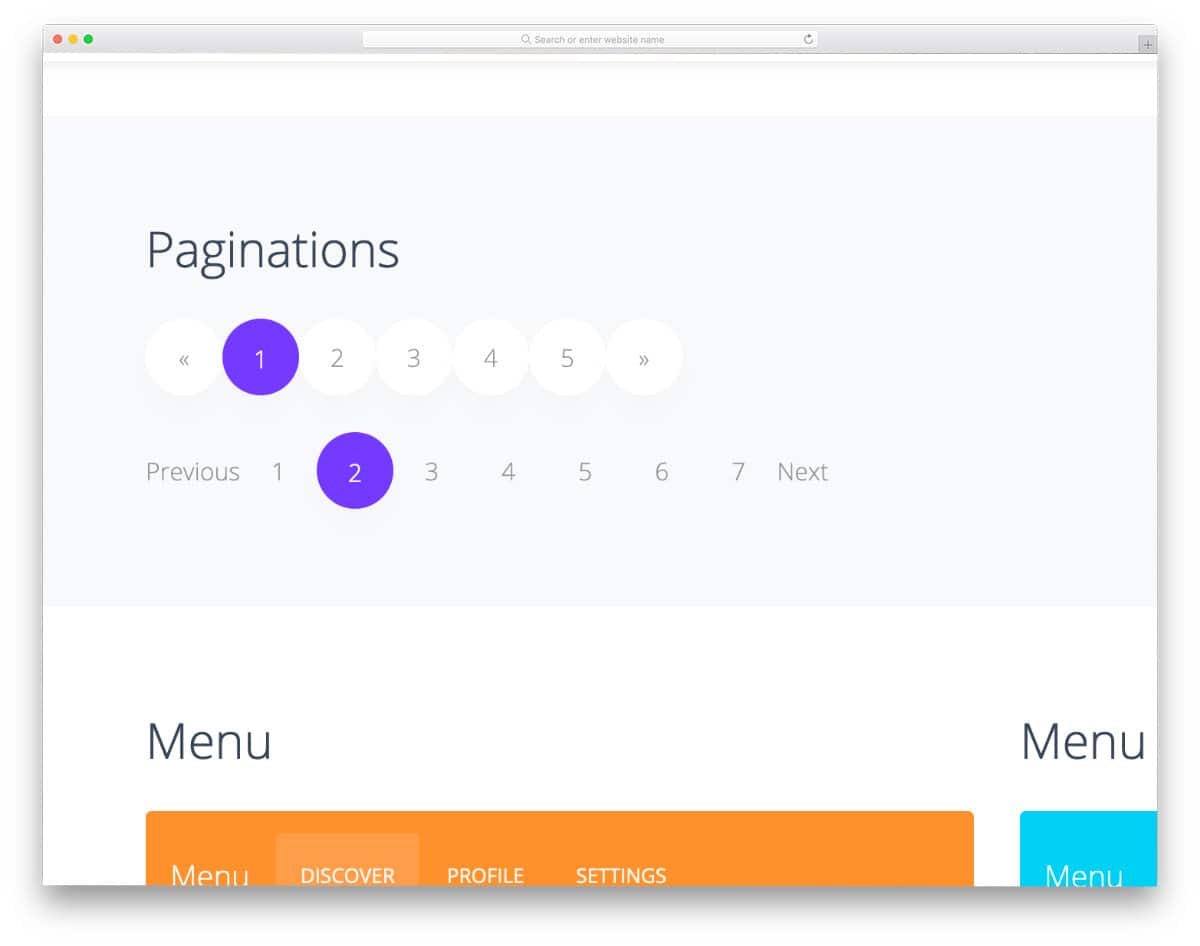
10. Set Up Pagination
- Use pagination when you have a long list of content items that would be cumbersome to display on one page, such as blog archives, product listings, or search results.
- Paginate when you want to balance loading speed and ease of navigation; typically, this is done when there are more than 10-20 items.
- This process makes it easier for Google to index your site improving your ranking.
11. Optimize User Experience
- “Load More” or Infinite Scrolling: As an alternative to traditional pagination, you can use “load more” buttons or infinite scrolling to show additional content. Be cautious with this approach, as it can impact SEO if not implemented carefully. If you use JavaScript for infinite scrolling, ensure search engines can still access and index paginated URLs.
- Clear Navigation: Make sure pagination links are easy to click and understand. Avoid hiding pagination links or making them difficult to see.

12. Understand the Basics of robots.txt
- The robots.txt file is a text file located in the root directory of your website (e.g., https://example.com/robots.txt).
- This file gives instructions to search engine bots on which parts of the site they can and cannot access. Each line typically consists of User-agent (which bots the rule applies to) and Disallow or Allow directives.
- User-agent: Specifies which bots the following rules apply to. Use * to target all bots or specify individual ones (e.g., User-agent: Googlebot).
- Disallow: Blocks bots from crawling specified pages or directories. For instance, Disallow: /admin/ prevents bots from crawling the /admin directory.
- Allow: Permits bots to crawl specified areas within a directory that’s otherwise disallowed.
Block Unnecessary Areas from Crawling
- Admin and Login Pages: Disallow: /admin/ or Disallow: /login/
- Internal Search Results Pages: These add little SEO value and can lead to duplicate content. Example: Disallow: /search/
- Thank You Pages and Order Confirmations: These are for user interactions and not useful to search engines: Disallow: /thank-you/
- Duplicate Content Directories: Such as archives, tags, or other duplicate content areas on CMS-based sites.

Conclusion
Technical SEO is the foundational pillar for optimizing a website to ensure search engines can crawl, index, and understand its content efficiently. By focusing on critical elements like page speed, mobile optimization, structured site architecture, and secure connections, businesses can enhance their site’s performance, user experience, and organic search visibility.
Each component, from addressing crawling errors to implementing schema markup and managing duplicate content, plays a vital role in building a technically sound website that meets both user and search engine expectations. Ultimately, mastering technical SEO ensures your website not only ranks higher but also delivers a seamless and engaging experience to visitors, paving the way for sustainable online success.